 DigiMax
DigiMax译者注:
Look-alike模型是我们关心的领域。
做数字营销的朋友们,希望打破流量的铁律——随着流量数量的增大,流量的质量必然会逐步下降。流量质量下降的原因,本质上就是因为随着流量数量的增加,人群的聚焦性也必然逐步降低,寻找目标人群的难度加大,致使非目标人群的比例也随着流量的增加而增加。因此我们也都知道,质和量无法兼得,智能平衡。
Look-alike是一个有可能打破流量铁律的方法,它的思想是在流量扩张的同时,确保增量流量背后的人群与最初高质量流量的人群具有相同的特征。
Look-alike一定都是基于一个基础的算法,普遍理解的方法是归纳高质量人群的人口特征,然后在更大的流量范围内找具有类似人口特征的人。但是,这个方法实际上操作起来的难度很大,原因种种。那么,是不是可以用其他的方法?这篇文章阐述了另一种更可行的方法,即,通过行为(而非人口属性)的归纳,加上监督学习,实现更合理的look-alike。
被吹嘘的Look-alike模型和基于行为特征的Look-alike
我之前曾在博客里为“大数据”大唱赞歌。我们曾经讨论过最优化算法和可以利用大数据来揭示的洞见。我一次又一次听到的问题是“首先,你是否能把这些洞见变为可实施的方案计划?”“其次,这真的管用么?”。
- 不要买任何你不懂的东西;
- 如果一个东西你无法知道是否会起作用,不要购买;
关心一个机器学习驱动的神经网络学研究,并带有判别分析?
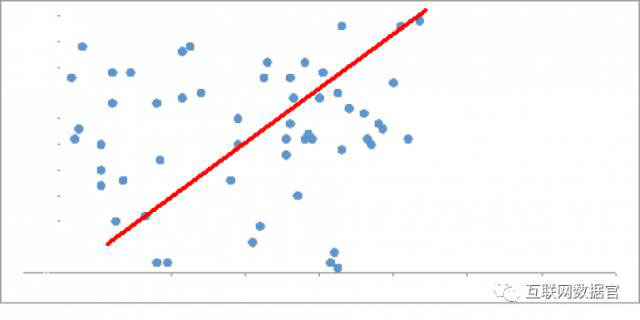 红线代表了一个公式,或者说,一种模型来描述用户。离线越近的点对用户特征的描述就越准确。但是,你注意到这条线只径直穿过了一个点,另有其他几个点只是碰触到了线。这条线描述了理想的用户,但是真正的理想用户其实很少。在很多案例中都是这样,因为模型为了更好的拟合而太过细化。如果你的典型用户只有不多的特征符合这些变量,那即使有200多个变量,在真实世界中不会给你什么好处。所以应该怎么做呢?大多数媒体会放宽这个模型的拟合条件。他们会设置一个数据阈值,比如说10%-15%的容差。他们中的一部分甚至会根据他们想要覆盖的用户数量凭空改变拟合。换句话说他们是在根据想要为你投放的广告数量来定义模型的。
红线代表了一个公式,或者说,一种模型来描述用户。离线越近的点对用户特征的描述就越准确。但是,你注意到这条线只径直穿过了一个点,另有其他几个点只是碰触到了线。这条线描述了理想的用户,但是真正的理想用户其实很少。在很多案例中都是这样,因为模型为了更好的拟合而太过细化。如果你的典型用户只有不多的特征符合这些变量,那即使有200多个变量,在真实世界中不会给你什么好处。所以应该怎么做呢?大多数媒体会放宽这个模型的拟合条件。他们会设置一个数据阈值,比如说10%-15%的容差。他们中的一部分甚至会根据他们想要覆盖的用户数量凭空改变拟合。换句话说他们是在根据想要为你投放的广告数量来定义模型的。
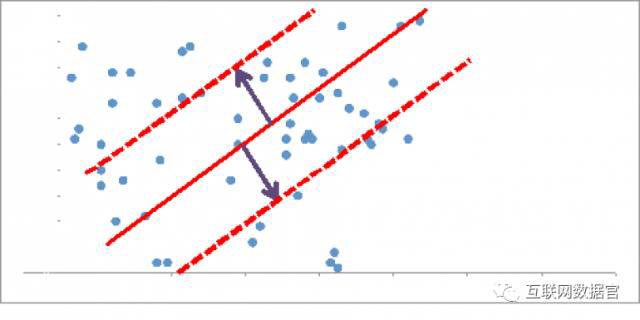
如上面的图解所示,广告会被两条虚线中间区域的用户看到。这涵盖了更多的用户。然而,这些用户中有的离原始模型很近,有的则离得很远。导致的结果是,广告的表现可能变好或者变坏,取决于广告收看者离最佳拟合线(理想用户)的远近。 当你依据拟合度搭建模型然后在现实世界用之来选定投放对象时,你能到达目标利润很可能会有所偏离。
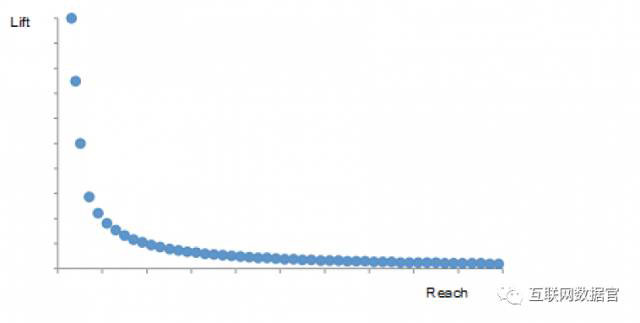
曲线上的每一个点都代表了一种我们可以定为目标的行为。从定义上说,曲线上每个行为/点作为广告主的营销目标都是同等有效的,因为这些行为/点都代表了覆盖率和广告表现的平衡状态。为客户工作的时候,我们经常会为客户的营销目的选择正确的行为截点。通常我们会从平均转化率5倍的点开始讨论,然后从这里向上或向下发展。取决于曲线的陡峭程度,比如说你也许会覆盖到那个提升度水平下我们人群库里10%的人群。这会在广告表现和人群覆盖之间达到一个好的平衡。想要覆盖更多的人?我们可以把覆盖率提高20%,但是这会导致聚合提升度下降到3x的水平。
- Tribal Fusion依据广告表现来定义我们的模型,并且告诉你有多少人会在这个前提限制下被覆盖。作为结果,你知道应该期待什么。这与基于合适度的模型有很大不同,在拟合度模型中,你先描述你的用户,然后希望能在真实世界中希望有个好结果。
- 这个模型独立于数据深度就可以起效,我们关注单个的高提升度用户行为,而非试图在模型中找到具有全部特征的用户。
-
这个模型透明可见,不只是告诉你模型中的单个的行为组分,我们也为你提供工具方便你查阅。Tribal Fusion的模型为所有人敞开,你可以查看 <Deep Dive, our audience diagnostics tool for advertisers and agencies>