 DigiMax
DigiMax这是我的半小时读懂系列的一篇新的文章。这篇文章不会用更难懂的技术术语去解释本来已经很难懂的技术与概念。事实上,我们只要知道,隐私计算技术在数字营销领域里的关键应用,以及背后的原理即可。
当然,这个话题非常非常庞大,并不是三言两语能说清楚的。但相信你读了我这篇文章,会清楚很多一直以来在心里模模糊糊的东西。
01 企业自己的数据,在数字营销中越来越重要
即便没有法律的限制,一方数据在应用中也涉及到泄露企业的机密信息的可能性。如果我是广告主,在我将自己的一方数据拿给媒体用于找人投放的时候,我确实会非常犹豫。
法律限制、保密需求,与让一方数据发挥真正的价值产生了严重的矛盾,而这样的矛盾,目前只有隐私计算能够很大程度上地缓解。
02 撞库
为了实现连接与打通这些消费者数据,数据中的ID至关重要,这个ID必须是广告主和媒体共同利用的ID类型。比如,广告主和媒体双方都用手机号码识别用户,或者都用设备ID(deviceID)识别用户。
现在,另一个至关重要的问题需要解决,那就是我打了双引号并且加粗了的“交给”二字。
广告主是如何将自己的一方数据连同ID一起“交给”媒体的呢?
过去,媒体提供给广告主一个上传数据的操作界面,广告主把自己的一方消费者数据,上传给媒体就可以了。
最开始,这些一方消费者数据的上传,是明文的。
但这么做,广告主风险巨大,媒体也渐渐不想接受这些明文数据。因为媒体若接受了这些数据,它也要承担法律责任,而广告主随意上传明文消费者数据且不说会泄露消费者个人信息,它自己的商业机密也被泄露了。
所以,媒体之后,都要求广告主上传经过加密的消费者数据(MD5或者SHA256加密)。
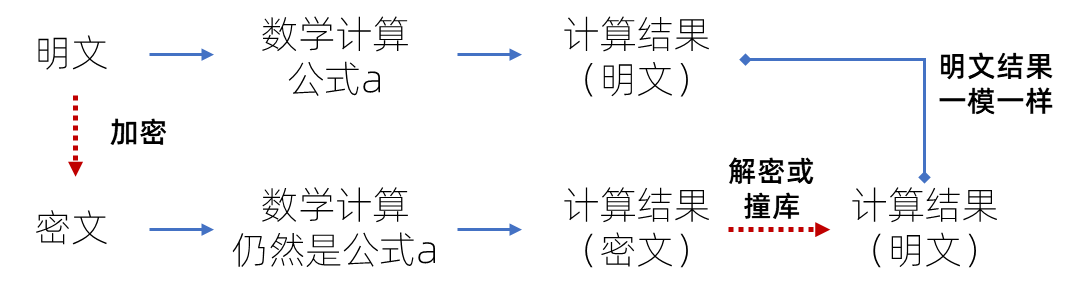
MD5或者SHA256,都是不可逆的加密。也就是说,不可能通过加密之后的密文还原为原文。加密了之后如果把原文完全毁掉并且忘掉了,想要找回原文是不可能的。当然,不能通过密文还原为原文,不代表不能用别的方法还原为原文——这一点极为重要,也是我们后面隐私计算能够实现的基础之一。
假如,我用SHA256加密了一段文字:“我爱公众号宋星的数字观”,变成了密文
“43d24306cf8a96d5b47f33114bdc66ef0c32cd26b639a4f71f5dfe13c65bce43”。然后我忽然得了失忆症,忘掉了原文是什么,而且我也没有任何记录记下我的原文是什么。现在我手上只有这段完全看不懂什么意思的密文。
按道理讲,我永远也不可能再知道这段密文对应的明文是什么了。
但天无绝人之路。正巧我的朋友,他也曾经加密了很多文字,其中也包括“我爱公众号宋星的数字观”这十一个字。
并且,他没有丢掉他的原文和加密密文的对应记录。
我于是去找他,希望搞清楚我的密文“43d24306cf8a96d5b47f33114bdc66ef0c32cd26b639a4f71f5dfe13c65bce43”背后到底是什么原文。
他把这个密文跟他所有的密文做一个vlookup的匹配,或者干脆来个Ctrl+F,直接就找到了他那边的同样的密文,然后对照着他的原文和密文对照表,他轻松找到了“我爱公众号宋星的数字观”。

上图:撞库
虽然是用加密的密文进行匹配,但是用原文密文的对照表一对照,也就知道了明文是什么。
这种方法,有一个学名,叫“隐私集合求交”,也被俗称为“安全求交”。但,实际上,“安全”二字很勉强,它本质上就是行业中常说的“撞库”的方法。
你会说,这样加密还有什么意义,只要保留着加密的明文和密文之间的对应关系,那么什么不可逆加密之类的,都照样会被破解。广告主就算把消费者的ID都加密了,上传给媒体,媒体照样还是很有可能把这些密文对应的ID给找回来。
并不是没有意义。上面这些不可逆加密的方法,确实不妨碍媒体还原广告主上传的消费者ID。但数据传输的中间过程中,例如需要由第三方经手的时候,数据万一发生泄露,消费者ID明文被暴漏的风险大大降低了。
比如,我是广告主,我找一个agency帮我上传相关的数据给媒体。在明文操作的情况下,agency可以拿到这些消费者ID,并且agency的员工有可能获得这些ID,这是很不安全的。但是,如果加密了,就算agency拿到了这些密文,也不会有大量的手机号码和对应的密文的对照表,风险也会更小。
讲到这里,跟隐私计算还没有什么关系。下面,隐私计算要出场了。
03 隐私计算为什么是必须的
另一些广告主,则有更高的要求,他们说,我的这些消费者,不仅仅只有ID,还有很多ID背后的属性,这些数据,能不能跟媒体或者第三方的数据结合起来,用于更好地洞察消费者?或者结合起来更好地圈选消费者?不过,这些属性不能透露给媒体或者第三方,也就是说,要在不给媒体或者第三方提供数据的情况下实现基于一方、二方(或三方数据)相结合的人群洞察和圈选。
这也是隐私计算可以解决的问题,即在不共享消费者属性数据的情况下,实现对属性数据的应用。
这些应用对于实现一些重要的数字营销场景至关重要,毕竟,数据如果不能够连通起来,数据的价值就大打折扣,数据在数字营销上的作用就得不到充分发挥。可以这么说,今天的数字营销,如果没有隐私计算的帮助,很多高级的玩法都无法实现。
我们先看看“广告主ID保密情况下的ID匹配与数据应用”问题如何通过隐私计算加以解决。
04 在ID保密情况下的ID求交与数据应用
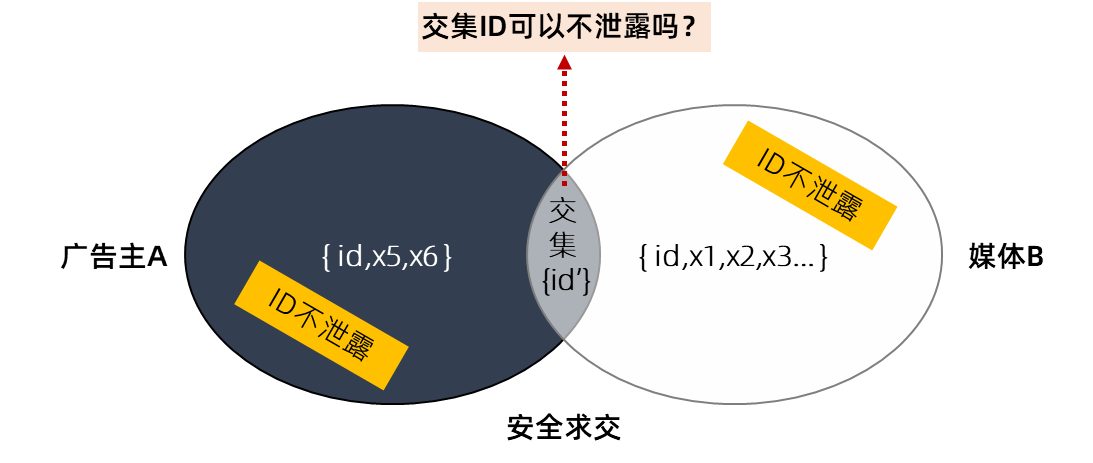
上图:交集ID可以不泄露吗?
因此,必须解决这个问题。
媒体,当然也就不知道这5万个手机号码中到底哪些是广告主的消费者了。广告主的ID就此实现了保密!
这种利用“掺混淆数据”保护秘密(隐私)的方法,被称为“差分隐私”。差分隐私有很多方法,这里讲的只是一种最容易理解的方法。其他各种掺入混淆数据的方法,要基于各种各样的算法,以保证混淆的效果,这里就不多介绍了。
加入了差分隐私的ID匹配,也被称为“匿踪安全求交”。
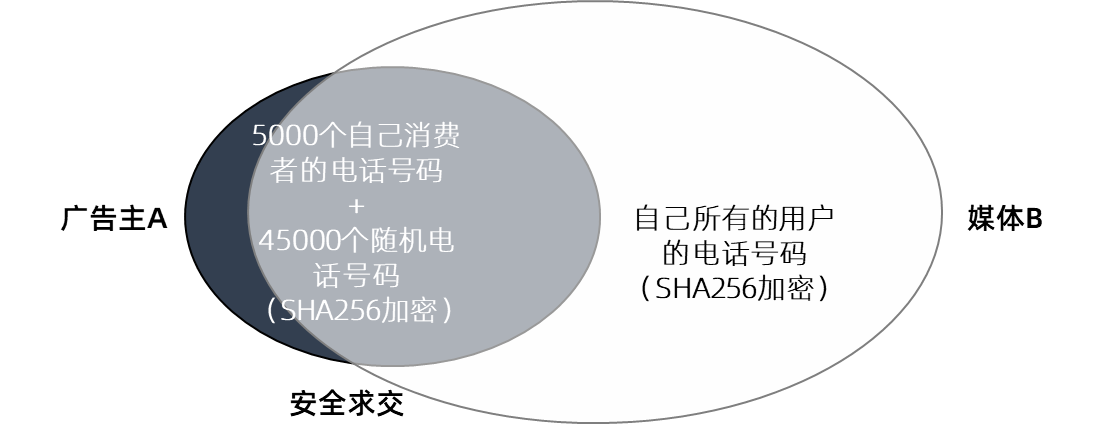
上图:基于“混淆差分”的安全求交
可信第三方
然后C帮助A,跟媒体(B)进行数据匹配。匹配完成后,B将自己的数据结果(个体级别的用户属性数据),以加密的形式发给C。
C针对B发回的加密属性,把混淆ID的加密属性去掉(剥离),然后计算广告主5000个手机号码中能匹配到的那些人的加密属性,并且归纳出这些人的共性特征。这些共性特征,不再带有个人属性,而是统计级别的数据,所以不再涉及到广告主A的消费者的ID。并且这些共性特征是由媒体B发来的加密属性计算出来的,因此,也是加密状态。
第三方C再把这些共性特征返回给媒体B,媒体把这些加密状态的共性特征解密,之后寻找与这些共性特征相同或者相近的人群,帮助广告主进行广告投放。
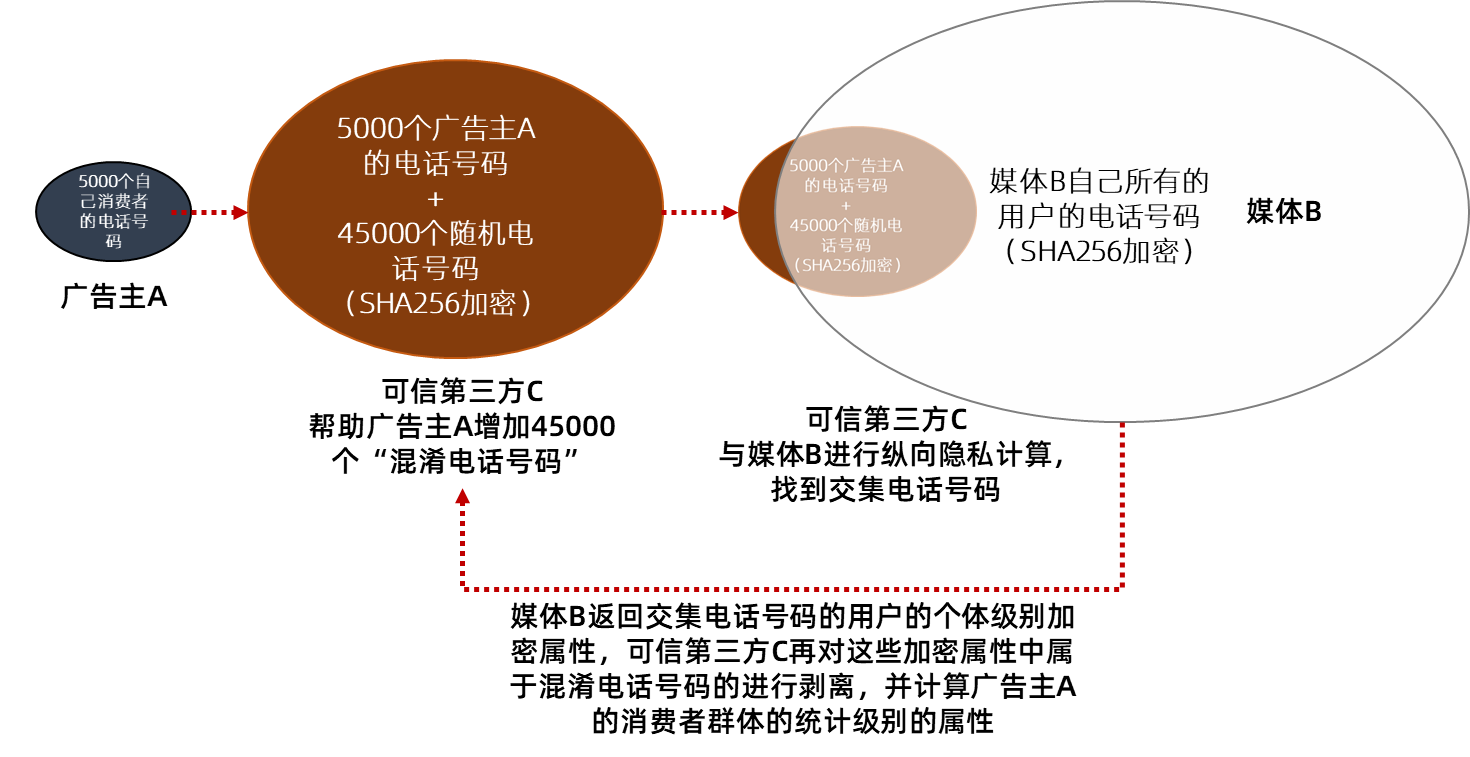
上图:加入可信第三方的匿踪安全求交
这样,广告主A没有暴露自己真正的消费者ID;媒体B也没有透露自己这些ID背后的属性;第三方C,帮助A和B完成了数据匹配,也计算出A消费者的共性特征,却也不知道这些特征具体是什么。只要C信守诚信,不泄露A交给他的加密的消费者ID,那么整个过程,就是相当安全的。
这就是隐私计算在数字营销上的一个非常典型且重要的应用。
05 对交集ID进行保密的进一步优化
当然,这种方法也不能说一无是处,媒体会强调,广告主的数据会在“可信硬件技术”之下被隔离保护起来,对广告主数据的操作,也是在这些硬件内进行的,并不会被泄露到这些硬件之外。
可信硬件技术,也在行业中被俗称为“数据安全岛”。
可信硬件技术主要解决下面的问题:
1. 数据独立(data separation):存储在某个分区中的数据不能被其他的分区读取或篡改。也就是说,广告主用于安全求交的ID,是不会被放到除可信硬件之外的地方的。
2. 时间隔离(temporal separation):公共资源区域中的数据不会泄露任意分区中的数据信息。计算资源,例如CPU,也有专门隔离的时间切片,来处理可信硬件中的数据。
3. 信息流控制(Control of information flow):
除非有特殊的授权,否则各个分区之间不能进行通信。
4. 故障隔离(Fault isolation):一个分区中的安全性漏洞不能传播到其他分区。
如果媒体严格采用可信硬件技术及管理,确实能够确保广告主提供的ID不被挪作他用。当然了,媒体是不是都能严格自律,我们可以看他们获得的执行标准的认证,比如《信息安全技术 可信执行环境服务规范》认证之类。不过认证这东西也不能100%全信,具体哪个媒体合格,哪个媒体不合格,就不在本文讨论的范围了。
在2022年的一个新闻稿中,某个数据科技公司提到,他们的技术能够:“无需安全求交、不泄露交集ID、在全匿名数据集下进行联邦学习的技术难题,真正符合《数据安全法》和《个人信息保护法》的要求,进一步加强了用户数据安全和隐私保护。”
真的可以吗?我的客户和我见过的媒体都还没有采用,所以,我暂时还不能给出肯定的回答。但看到这个消息,至少让我觉得这个方向是有可能的。
06 ID求交(撞库)和可信硬件环境下的数字营销应用场景
媒体与这些ID进行安全求交。
求交之后,能够匹配到的ID,媒体也把这些ID对应的媒体端所拥有的属性数据,上传到该硬件环境中。
此时,这个硬件环境中,也就是数据安全岛中,就集合了交集ID,以及每个ID所对应的广告主的一方属性标签,和媒体的二方属性标签。
媒体基于这些ID和属性标签,以及基于这个可信硬件环境,为广告主提供一个圈选人群的界面。广告主在这个界面中,根据自己的需求,基于一方、二方的属性标签,进行人群圈选。
比如,广告主A,跟媒体通过安全求交,匹配了1000万人。这1000万人,广告主自己的标签是过去一年内的购物数据和私域内的互动行为数据。而媒体端,则是这1000万人的社会属性和兴趣爱好数据。
基于联合人群圈选的解决方案,广告主A可以选择,在过去3个月内购买了某类商品,且兴趣爱好是旅游的一线城市的20-30岁的女生。
圈选之后,媒体基于圈选结果得到的ID,进行广告投放,或是按照广告主A的要求做其他营销触达。
或者,广告主也可以先基于自己的一方数据标签,圈选出人群,然后再看这些人群的二方属性是什么。从而更好地洞察自有消费者。
比如,广告主A基于自己的一方数据,圈选出3个月内购买某类商品的人群,然后再在这个界面上要求媒体对这些做画像。媒体会提供这些人的二方属性的统计报告。
07 安全求交之外的隐私计算应用
但可惜,每个汽车主机厂最多的样本也只有200万个。于是多个主机厂联合起来,他们不分享任何的ID给彼此(不做安全求交),而是各自基于自己的样本先计算一个“粗糙的”购车预测模型。然后各自把自己计算的模型结果上传到一个第三方,第三方基于这些车厂的模型,整合出一个新的模型。并把这个新的模型下发给各个主机厂,再次做计算,以优化这个模型的“梯度”。
至于什么是梯度,就不解释了,太技术。你可以简单理解为,就是对这个模型里面的参数什么的进行进一步优化。
这样的过程多来几遍,直到这个模型靠谱了,就能够给每个车企使用了。
你看,每个车企没有把自己的任何样本公开出去,却都得到了靠谱的购车预测模型。
所谓横向联邦学习,这里的横向,就是指,参与计算的各方,他们拥有的样本的ID并不相同,但是这些ID的属性类型是相同的,比如购买者都有在私域中的各种同样的行为类型(查看车型、查看购车金融、询问客服之类的,每个车企的私域都有这些相同的交互功能)、同样的社会属性类型等。而纵向联邦学习,则是样本的ID相同,而ID背后的属性不同。
讲到这里,终于把我想讲的基本上讲完了。能读到这里的朋友,应该对隐私计算在数字营销上的原理和应用有了更全面的理解。不过,还有一些问题我没有能在这里进一步阐述,比如,这些应用场景具体起到什么作用,对不同行业的意义是什么,又如,隐私计算在数字营销中的合法合规性问题。这些内容,就不再写在文章中了,否则文字太多了。感兴趣的朋友,欢迎上我的线下课《数据化增长:数据驱动的新数字营销》(点击查看具体课程介绍)进一步了解学习。
以上。